Abstract
Precise worldwide geolocalization is a challenging task due to the variety of images taken from different geographical and cultural landscapes. Existing work on worldwide geolocalization uses machine-learning approaches to estimate the location of images by constructing mappings between imagery data and their corresponding coordinates or geographical regions. As such, existing models cannot leverage online or contextual information related to their task, and are unable to effectively make precise street-level(1km) predictions. We present GeoAgent, a Large Multimodal Model(LMM) powered agent that completes precise geolocalization tasks by leveraging online information such as Open Streetmap, satellite imagery, Google Street View, as well as other machine learning models for image retrieval and geo-estimation. We evaluate our model on the image geolocalization benchmark IM2GPS3k and find that it outperforms the previous SOTA in street-level geolocalization by an accuracy of 20.7%. Overall, we demonstrate that multi-modal vision agents' potential to be applied to real-world, complex tasks that require reasoning.
Video Demo
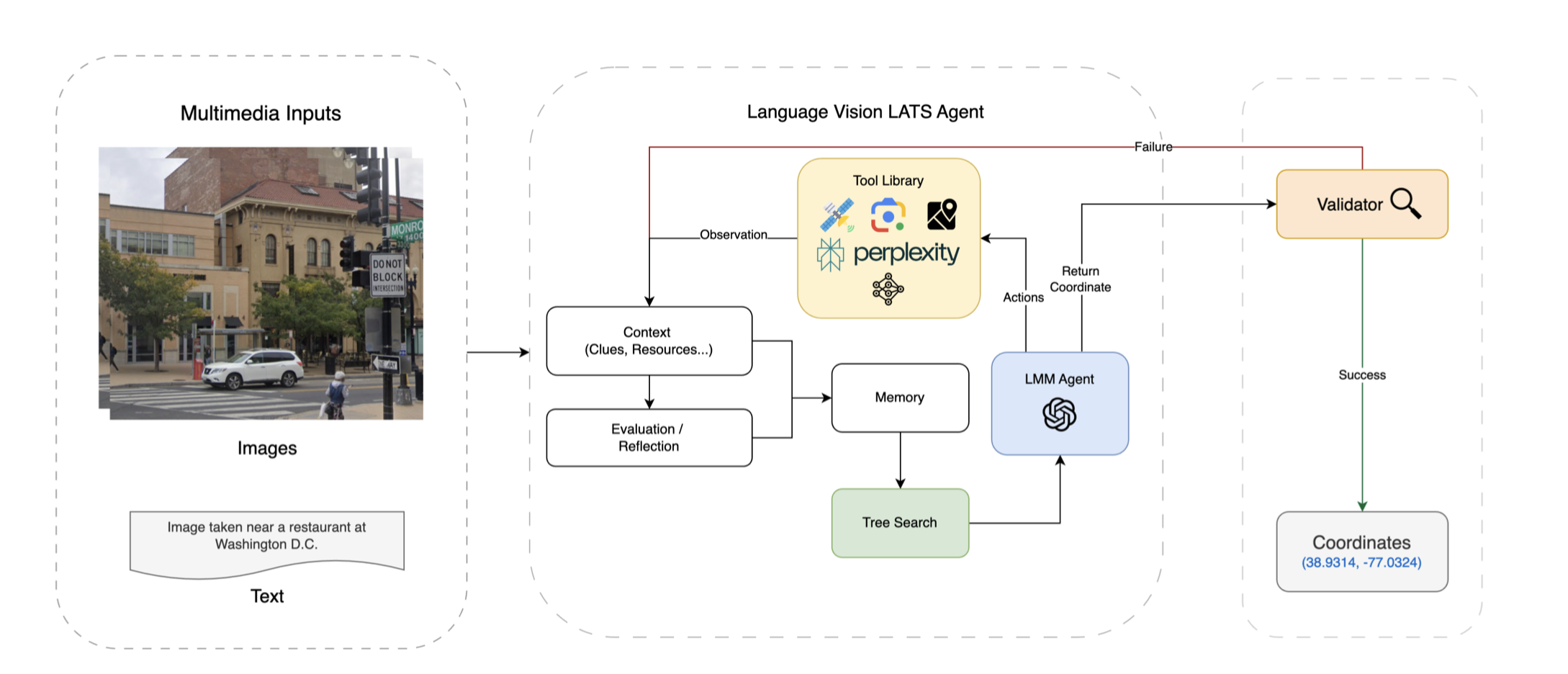
GeoAgent's workflow; GeoAgent is a multi-modal agent based on Language Agent Tree Search that specializes in conducting precise world-wide geolocalization. GeoAgent has access to tools such as Google Maps, satellite imagery, Perplexity, and more.

Visualization of GeoAgent's investigation on a tweet using GeoAgent Client. GeoAgent uses Google Lens on a video frame to identify the location; and uses perplexity and satellite imagery to corroborate the location before reaching a final conclusion. Original tweet: http://archive.today/NrTBv, Full screenshot of reasoning trace: https://sh.jettchen.me/ga-trace-1
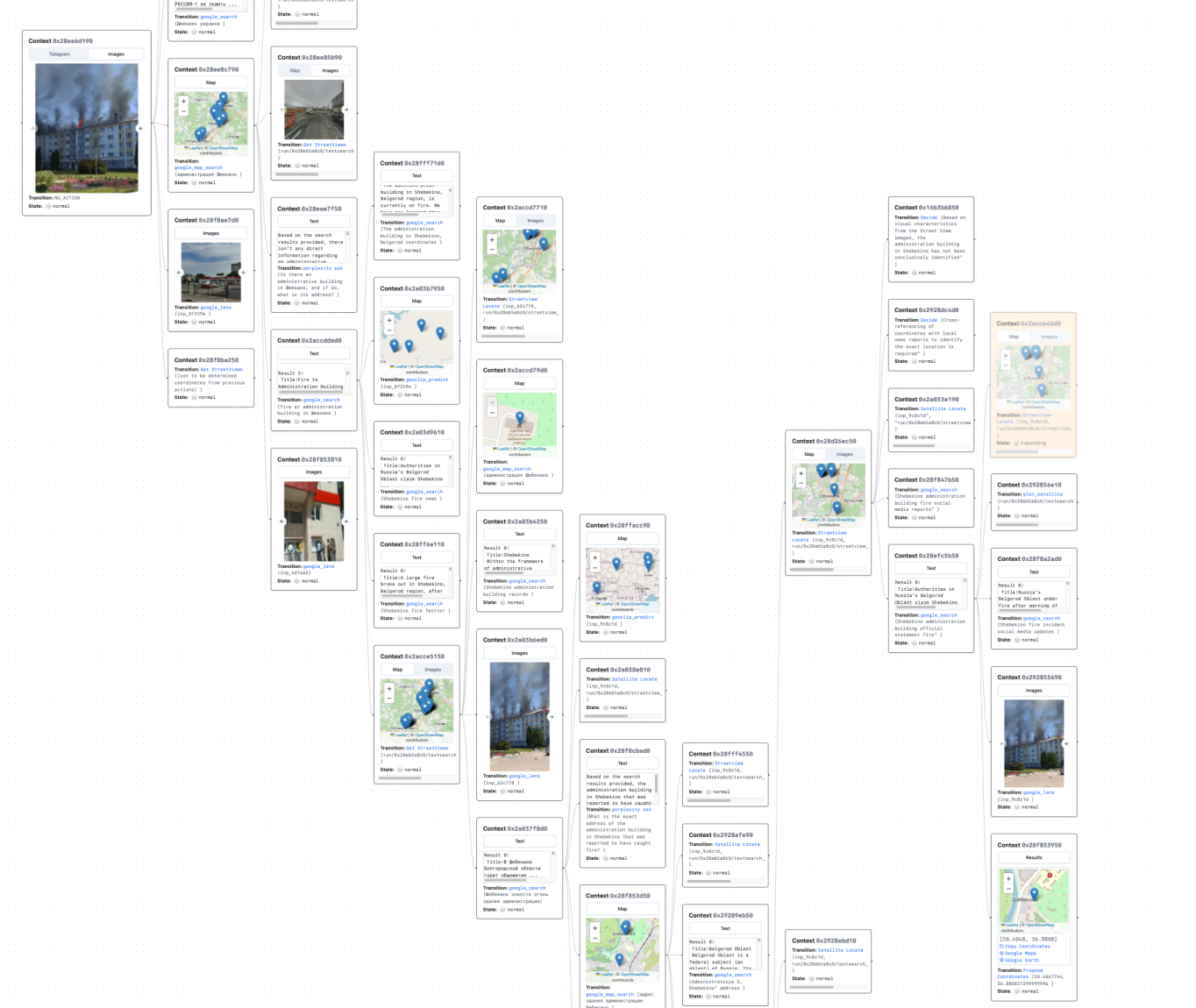
GeoAgent Demo Trace 2
BibTeX
@inproceedings{chen2024geoagent,
title={GeoAgent: Precise Worldwide Multimedia Geolocation with Large Multimodal Models},
author={Chen, Jett},
booktitle={NeurIPS 2024 HighSchool},
year={2024}
}